Workspace
To access the main AnFiSA screen just open the AnFiSA UI in browser.
By default after the local installation, the AnFiSA UI is available on http://localhost:3000.
Datasets tree
All data regarding variations are represented as datasets.
Each dataset is a set of variations for one or multiple samples.
The AnFiSA Datasets are defined in two main groups:
Primary datasets usually represent full exome/genome variations set of several experimental samples.
It can contain several million or even billions of variations.
The user can filter and process data from primary datasets, but can’t view the variations directly.
Secondary datasets are the result of filtering variations from primary datasets.
Each secondary dataset is a descendant of the ancestor XL dataset.
A secondary dataset can include not more than 10000 variations.
The user can do all filtering operations with secondary datasets the same way as with XL datasets.
In addition, the user can directly view the variations list in a secondary dataset.
To start work with AnFiSA user should select the primary dataset.
Note: the derived datasets can’t be selected directly.
The user need to open it via primary dataset.
Primary dataset info
After selecting the primary dataset user can see the dataset information page:
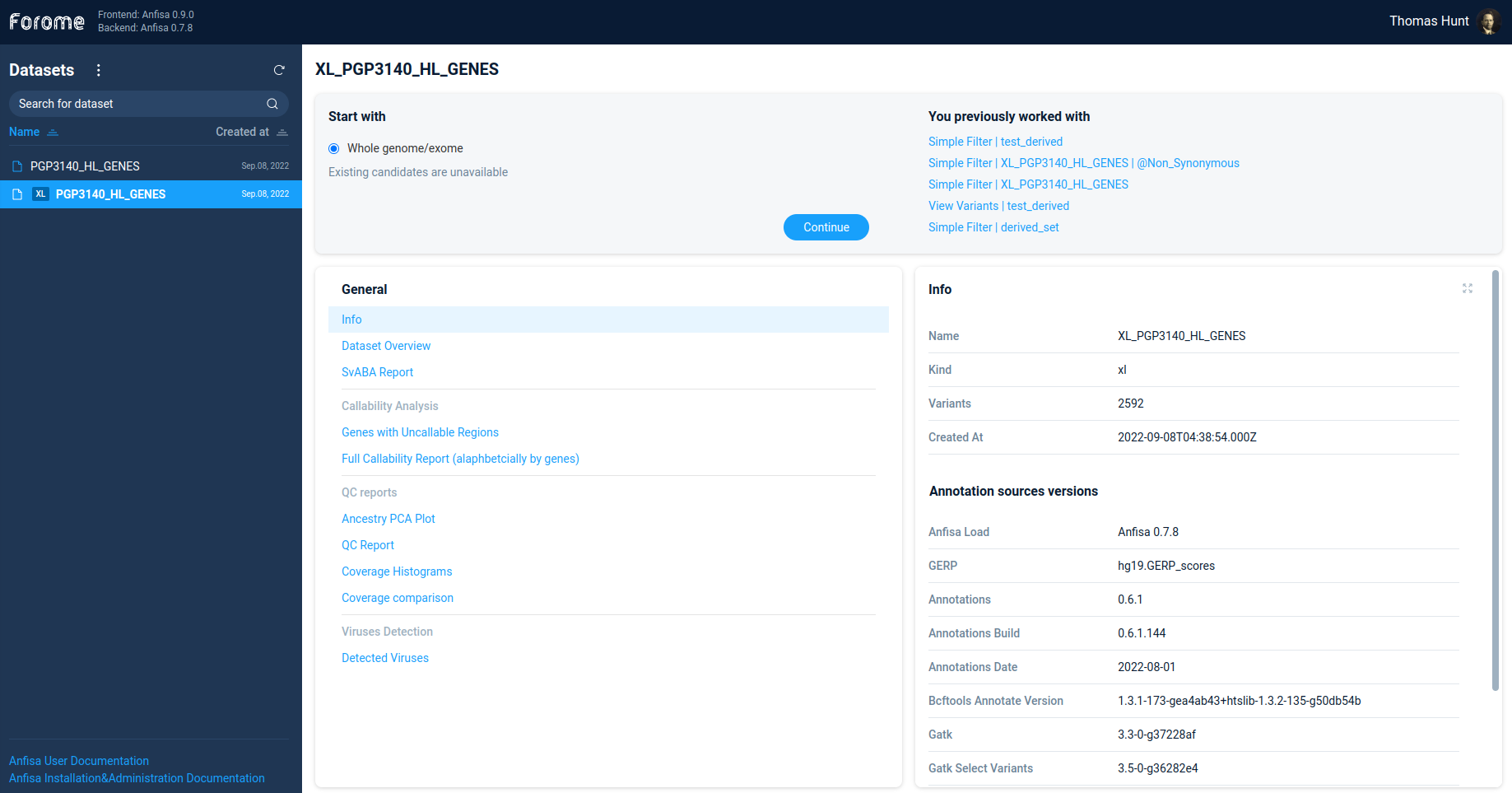
Each section in the left tab contains some set of information which is displayed in the right tab.
The information can be presented as plain text, tables, links, etc.
Here is a brief description of the available sections:
- General
Info
Dataset Overview
SvABA Report
- Callability Analysis
-
- QC reports
Ancestry PCA Plot
QC Report
Coverage Histograms
Coverage comparison
- Viruses Detection
-
Here is the brief description of info sections:
SvABA Report
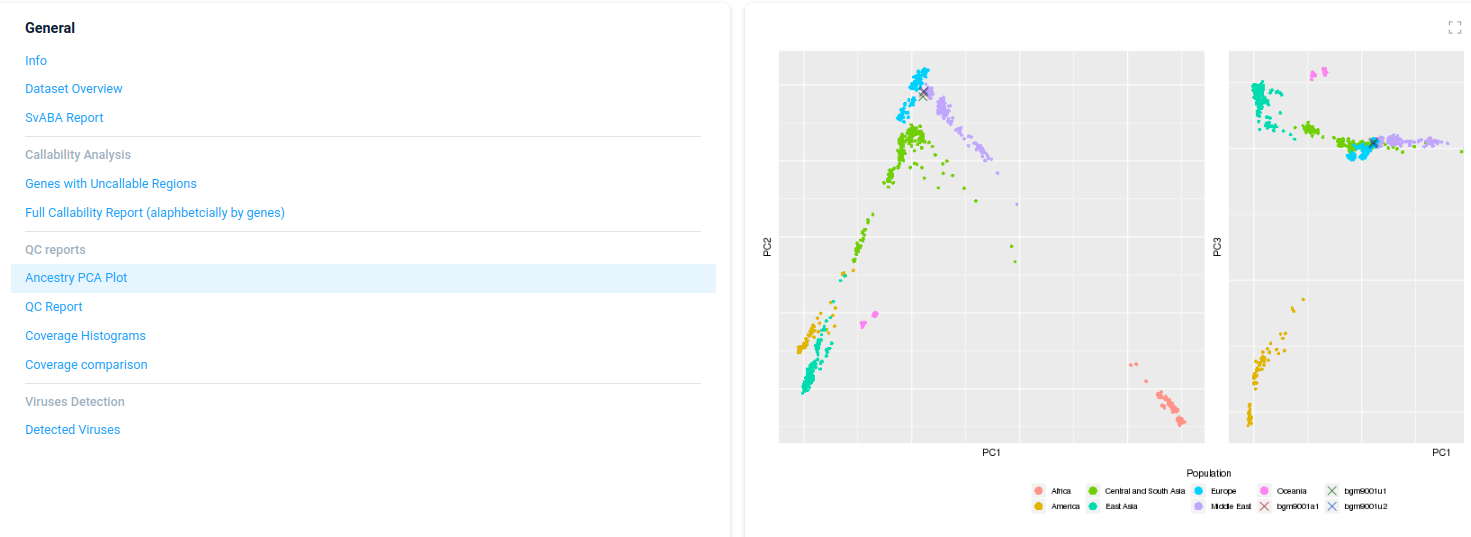
Ancestry PCA Plot
Primary dataset analysis
To start analysis for the primary dataset user should select the “Start with” and choose the option “Whole genome/exome”.
After this, the user will see the possible list of filtering options in the “What’s next?” panel.
For custom data filtering AnFiSA supports two very powerful methods, which are described in
subsequent sections:
Filter refiner
Decision tree
The “What’s next?” panel also contains several built-in analysis types
(ACMG analysis, Phenotype based analysis).
If fact, each pre-built analysis type is just a quick access to the corresponding group
of predefined decision trees. One can choose a decision tree from built-in analysis types,
or manually choose it in the “Decision tree” mode. The result will be the same.
The full list and description of predefined filter sets and decision trees is here:
Predefined filters
Next: Filter refiner
Table of contents